
Self-driving cars
Touched-up selfies
Netflix recommendations
Chatbots that write like people
Virtual assistants that talk like friends
Every last one of the billions of daily Google searches…
Artificial intelligence (AI) is all around you, and it’s only getting more pervasive. But if you start looking into how it works, you’ll immediately run into a few questions about the concepts surrounding it: What is deep learning vs. machine learning? And how do artificial intelligence, machine learning, and deep learning relate to one another?
There are simple answers to these questions as well as complex ones, and then there’s the math behind it all, which is so complicated that it’s probably best to set aside for now. At any level of understanding, these answers are important—particularly for brands and marketers. After all, AI increasingly governs interactions with customers, as illustrated by the rise of voice AI technologies.
At ReadSpeaker, we use deep learning to create advanced synthetic speech that gives voice to consumer touchpoints like voicebots, smart home devices, AI assistants, and conversational AI platforms of all descriptions. We’ll discuss the use of AI in speech synthesis in detail at the end of this article; it’s the perfect illustration of a practical use for deep learning. But first, if you want to understand machine learning, AI, and deep learning, start with a few key definitions.
Need a distinctive AI voice?
Find yours with ReadSpeaker
What do artificial intelligence, machine learning, and deep learning mean?
- Wikipedia’s definition of artificial intelligence is broadly accepted. According to the site, “AI is intelligence demonstrated by machines.” Wikipedia contrasts this with the “natural intelligence displayed by humans and animals, which involves consciousness and emotionality.” As for intelligence itself, that’s simply an ability to obtain information and use it adaptively.
- Machine learning is “the study of computer algorithms that improve automatically through experience,” says computer scientist Tom Mitchell, who literally wrote the book on machine learning.
- Deep learning is a form of machine learning conducted (for the most part) through deep neural networks (DNN). There are other ways to perform deep learning, but DNNs are far and away the most common in practical use today, so they’ll be our focus in this guide.
With these definitions in mind, we can ask our main question: What’s the relationship between machine learning, deep learning, and AI? Deep learning is a subset of machine learning, and machine learning is a subset of AI. However, deep learning has become so dominant in AI circles that, when someone mentions AI, it’s extremely likely that they’re also talking about deep learning; you can assume that any discussion of AI is also a discussion of deep learning (and therefore machine learning, too).
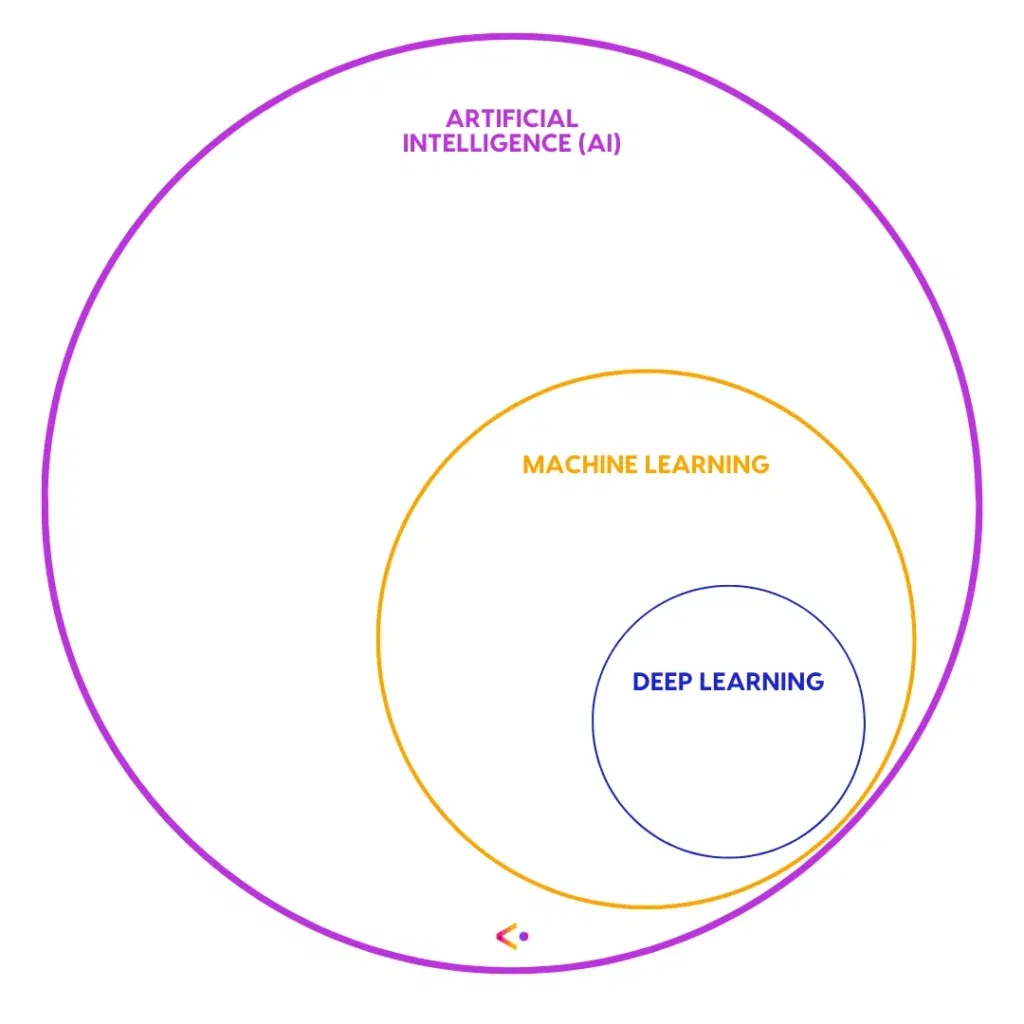
That’s the simple explanation. Now to go a little deeper.
Deep learning vs. machine learning: What’s the difference?
Remember that deep learning is a subcategory of machine learning. The difference in deep learning vs. machine learning is that machine learning includes all of the computational models capable of self-improvement through experience. Deep learning, on the other hand, uses one particular category of computational model: the deep neural network. We’ll explain deep neural networks in detail later.
First, we have some basics to cover. Why bother with machine learning (deep or otherwise) in the first place?
Before the availability of machine learning, computer programmers wrote complex lists of rules to perform computing tasks. For instance, say a traditional programmer wanted to get rich predicting stock prices. To design an effective price-prediction program, that programmer would have to figure out all the factors that affect the market—based solely on human observation and prior knowledge. If the price of oil rises, transportation stock prices may decline…and that’s just one factor among infinite others. Our poor programmer would be stuck coding them all by hand.
As you might expect, rules-based programming is not very efficient. It’s also not very effective. Human observation can only take us so far, and innate bias can lead to algorithms that simply don’t reflect the reality of the task they’re designed to perform. Our hypothetical programmer would have to find another way to get rich.
Machine learning offers an alternative to writing your own rules.
Machine learning allows programmers to automate rule-generation. That’s extremely powerful for solving complex problems—including challenges that humans don’t fully understand, like recognizing emotion based on facial expression. How can a programmer write rules when they don’t know the rules? In other words:
What is machine learning?
We’ve already covered the simplest answer to this question with Tom Mitchell’s definition: Machine learning is “the study of computer algorithms that improve automatically through experience.” On a practical level, you’re probably not interested in the “study of computer algorithms” as much as the specific machine that does the learning, right?
Put simply, to achieve machine learning, you need a machine learning model. That’s a computer program that gives you real results. Machine learning models can spot patterns in large datasets or predict the most helpful output for your given input. And at the core of any machine learning model, you’ll find a machine learning algorithm.
A computer algorithm is an ordered process, a series of logical steps that:
- Receives input data;
- Processes input data in some way, and;
- Produces an original output.
A machine learning algorithm, then, is an ordered process designed to improve itself as it’s exposed to more and more input data. So a machine learning algorithm does the computational work, while the machine learning model creates a user interface that allows people to run the algorithm.
There are lots of machine learning models available. They generally fall into one of three overarching categories:

- Supervised machine learning models function by creating associations between data points and the labels people put on them. For example, if you’re training a self-driving car system, you might start by labeling huge numbers of images: “tree,” “traffic light,” “pedestrian.” When you expose your application to more of this labeled data, it learns to predict what’s what in a novel situation—like driving down an actual street.
- Unsupervised machine learning models don’t need all those human-created labels. They categorize datasets on their own. For example, an unsupervised machine learning model might spot anomalies or outliers in a dataset. That makes it useful for AI tasks like predictive maintenance, which spots likely mechanical failures before they occur.
- Reinforcement machine learning models work a bit like animal training. The model’s given a choice of outputs for any given input. It chooses one, and the system records the output as “good” or “bad.” Over time, the system will learn to make more “good” decisions. Reinforcement learning is popular in robotics, where it trains physical machinery to perform well in novel environments (and most real-world situations are relentlessly novel).
To wrap it up, machine learning improves computational performance by deriving rules from data. Programmers working on emotion-recognition applications don’t have to personally understand the infinite gradations of a smile. Instead, they can expose a machine learning algorithm to millions of expressions, each labeled by emotion, and let the system figure out which is which—and thereby to “recognize” emotions when exposed to new images of expressive faces.
But while machine learning is always powerful, not all machine learning is “deep.”
What is deep learning?
In order to understand deep learning, you need to know about deep neural networks. There are other machine learning models that achieve what we call “deep learning,” but neural networks have eclipsed all the rest to the extent that you can safely assume any mention of deep learning is based on the neural network model—so much so that an effective (if not scientifically accurate) definition of deep learning could be “machine learning through deep neural network architecture.”
The neural network computation model was inspired by the connections of neurons within the human brain—but that’s only a rough analogy. When you get down to the details, human brains and neural networks are extremely different. Still, the metaphor is helpful for understanding the broad strokes of neural networks: Neural networks mimic the way the human brain works to process information.
Our brains learn by establishing repeatable patterns of electrochemical connections between neurons. A neural network does something similar. The neural networks, widely used in the 1990s, consist of three layers of networked processors, or artificial neurons: the input layer, a hidden layer, and an output layer. Each neuron receives input data, performs an operation on that data, and exports the results of the operation as an input to the next processing layer.
These neural networks are also called multi-layered perceptrons (MLP), and they efficiently solved some of the most vexing problems of their era. But with the increasing availability of larger datasets, and long strains of research breaking into practice, neural networks evolved alongside the dawning era of Big Data.
Here’s how shallow neural networks became deep neural networks.
The way computer scientists achieved this goal was to add additional hidden processing layers to their MLPs, creating a new computing model: Deep neural networks, or DNN. Technically, any neural network with more than one hidden layer is considered “deep,” but the models computer scientists use today feature dozens of hidden layers—as many as 30 or 40 in many cases.
But why? Why do hidden layers make this model so effective at performing complex computations?
Deep neural networks can express very complex mathematical functions more efficiently than standard neural networks. You can model any complex function with a traditional MLP that only contains a single hidden layer (that’s proven by the Universal Approximation Theorem, which, if you’re not a computer scientist, it’s best not to think about too much). But a shallow neural network is almost always less efficient than a deep one stuffed with multiple hidden processing layers. Here’s why.
Abstraction of local features gives DNN its power.
Deep neural networks process abstract representations of features, which are more robust than local representations. A DNN extracts multiple abstract representations as data passes through its multiple layers—the more layers, the more abstract representations the system can extract.
For example, say our goal is to train a neural network to classify images of dogs and cats accurately. If we feed millions of images into the neural network, the local features of these images may include:
- Shapes of eyes
- Shapes of ears
- Fur color
- Fur pattern
See the trouble? These local features are themselves highly variable; there’s no single color of fur that can differentiate a cat from a dog. You can’t make a one-to-one connection between a single local feature and the designation “cat.” Instead, we need to study abstract features: not just certain eye shapes, but the whole placement and appearance of eyes within a face. That helps the system categorize images as “cat” or “dog” based on abstract relationships between local representations.
Multiple hidden layers allow a DNN to learn more of these abstract features that add up to more informed classifications of cats and dogs. Programmers may not even know which features the DNN is extracting; we just know that when we pass enormous volumes of data (labeled images of cats and dogs) through the network, it maps a processing path toward more accurate categorization of new images.
To sum up, deep neural networks provide deep learning by passing data through multiple hidden processing layers to conduct more complex processes. It’s a powerful technology—so powerful, theoretically, that we have to ask another question: Why are we only beginning to use this computing architecture now, decades after it was theorized?
If deep learning is so powerful, why bother with “shallow” machine learning?
Deep neural networks are capable of handling much more complexity than their shallow machine learning cousins. However, that doesn’t make deep learning the only technique computer scientists reach for. Sometimes, shallow machine learning is the better tool for the job. When choosing deep learning vs. machine learning, computer scientists may opt for either—it all depends on the use case.
The fact is, deep neural networks draw a huge amount of computing power. That means they use a lot of computing power. They’re very expensive to run.
Shallow learning algorithms need less computing power, so they’re cheaper to operate. If you’re designing an AI-based service, you want to keep your software extremely efficient. So if a shallow algorithm—or even rules-based software—does what it needs to do, that’s a better choice than neural technology, regardless of the latter’s incredible power.
For example, text-to-speech software (which we’ll discuss more shortly) completes a task called “grapheme-to-phoneme translation,” or G2P. That’s just one of several tasks a TTS system complets, but you don’t get TTS without it. It’s the step in which software associates a combination of letters with a specific sound—how it knows “sh” should sound like shushing, for example.
A DNN-based system could absolutely succeed at G2P translation. But it would cost TTS operators a lot. You can accomplish the same thing with a G2P dictionary at a fraction of the price. That’s not machine learning at all.
The point is, deep learning is exciting, but it’s not always the best way to solve a particular software challenge. Shallow machine learning and rules-based code aren’t going anywhere anytime soon.
How did deep learning go from theory to practical application?
There are three reasons deep learning took so long to go from theory to everyday use.
- Hardware. When deep neural networks first emerged, we didn’t have hardware that was efficient enough to train DNNs. That changed with the development of modern graphics processing units (GPUs)—the development of which was hastened along by video game consoles, not the needs of academics. The GPU on a $200 video game console can be ideal hardware for training complex DNN models—much better than even an advanced central processing unit, or CPU.
- Big data. Large datasets weren’t as available in the early days of neural networks. To train a complex DNN model in a stable way, you need extraordinary amounts of data. In the early days of AI, that data wasn’t available. Now there are easily accessible platforms that allow researchers to collect billions and billions of data points every single day.
- Deep learning algorithms. Most importantly, scientists hadn’t yet devised the algorithms we use to keep highly complex DNN models stable during training. Early algorithms led to unstable models, which weren’t dependable enough for practical use. Thanks to the work of enterprising scientists, today’s deep learning algorithms can train stable DNN models to achieve consistent results. Here are three of the scientists who developed key algorithms that made today’s deep learning possible:
- Geoffrey Hinton is Chief Scientific Advisor at the Vector Institute, Vice President and Engineering Fellow at Google, and Emeritus Distinguished Professor of Computer Science, University of Toronto. He devised the fundamental algorithm used to train neural networks: backpropagation.
- Yann LeCun is VP and Chief AI Scientist at Facebook and Silver Professor of Computer Science, Data Science, Neural Science, and Electrical and Computer Engineering at New York University. LeCun helped to design a new class of DNN, the convolutional neural network (CNN), which we often use to analyze images.
- Yoshua Bengio is a computer science professor at the Université de Montréal and co-director of CIFAR’s Learning in Machines & Brains program. Along with fellow computer scientist Ian Goodfellow, Bengio developed a powerful model called a generative adversarial network (GAN), which pits two neural networks against one another in a competitive game to push output results to more accurate levels.
Together, these three scientists received the 2018 ACM A.M. Turing Award and were labeled the “Fathers of the Deep Learning Revolution.” The fact that this occurred as recently as 2018 helps to illustrate just how new deep learning is for practical, customer-facing applications—such as astoundingly natural text to speech (TTS), which is our focus here at ReadSpeaker.
Want to hear how lifelike neural text to speech can be? Contact ReadSpeaker for a personalised demo.
Request a demo
Neural TTS is a clear example of how machine learning, deep learning, and AI achieve real business goals.
ReadSpeaker uses DNNs to construct lifelike TTS voices for use in conversational AI systems and other synthetic speech applications (including all-original custom TTS voices to support your brand identity in voice channels). In fact, machine learning has a long history in the TTS field. However, before the advent of deep learning, the results were not especially lifelike; they’ve even been described as “robotic.” Suffice it to say, early TTS didn’t provide an outstanding user experience. To create positive associations with brands, companies need TTS voices that set users at ease; something more lifelike and welcoming. Deep learning makes that possible.
Deep neural networks led to higher-quality vocoders, a cornerstone of lifelike TTS.
Deep neural networks provide the power to predict more natural-sounding speech. One clear example of a deep neural network used for TTS is DeepMind’s WaveNet, introduced with a scientific paper in 2016. WaveNet represents a tremendous advance in terms of TTS quality; when trained on recordings of a human speaker, WaveNet produces extremely human-like speech. (Note that text to speech created using neural networks is called neural TTS.)
So what exactly is WaveNet? It’s a neural network-based vocoder. (It’s not the only one, anymore, either. Other neural vocoders include Parallel WaveGAN, FFTNet, and WaveRNN.) To understand how deep learning contributes to neural TTS, we need to explain what a vocoder is, what it does, and how AI makes it more effective.
What are vocoders, and how do they use deep learning?
A vocoder is a computer model that transforms abstract parameters into speech waveforms. In other words, it turns numbers into audible speech. Here’s the challenge: A speech waveform contains a tremendous amount of data. If you record a voice at a 48 kHz sampling rate, that means it captures 48,000 samples (tiny slivers of data) per second. The data—and the file sizes—add up quickly.
That makes it too costly to transmit a raw waveform. Thus, in practice, we compress waveforms into smaller chunks of parameters. That always involves some level of data loss.
Vocoders predict the loss to reconstruct a playable waveform. With DNN models trained on recordings of human speech, these systems get much better at predicting the missing data required for playback. As a result, they enable more natural-sounding TTS voices. But there’s another AI-based TTS model on the horizon: end-to-end speech synthesis.
What’s next for deep learning and artificial intelligence in TTS applications?
Deep neural networks don’t just play into the best contemporary vocoders; they’re also introducing a whole new approach to speech synthesis. Researchers at Google, ReadSpeaker, and other tech companies are working on end-to-end TTS models. What does that mean?
Today’s TTS systems generate speech in multiple steps; they start with linguistic pre-processing, create an acoustic model, and only then transmit predictive data to the vocoder. Each of these steps may require tweaking by computational linguists—in other words, most neural TTS still requires human intervention. The human knowledge embedded in these linguistic pipelines opens the door for bias and errors.
An end-to-end TTS model seeks to minimize human intervention by predicting accurate pronunciation directly from characters. Since the introduction of Google’s Tacotron, in 2017, the field has seen a proliferation of end-to-end speech synthesis models, such as Prosody and NaturalSpeech. It’s likely that end-to-end TTS is the next step in the evolution of synthetic speech.
Other research areas (many of which we’re pursuing in the ReadSpeaker VoiceLab) include:
- Creating more efficient neural TTS models that limit costs
- Developing a more compact, robust TTS model to bring DNN-powered synthetic speech to smaller devices and low-resource computing environments
- TTS that’s controllable for emotional speaking styles
- Multilingual TTS, so one voice model can speak multiple languages
- Adjustable speaking styles within a single TTS model
- Expressing the hidden, underlying aspects of speech that even linguists haven’t mapped out yet
In short, machine learning, AI, deep learning, and neural TTS are very much developing technologies—and they’re improvising faster than ever. Read more about the growing possibilities of neural TTS here.
We’ll end with a word of warning about machine learning, deep learning, and AI.
Everywhere you look in the business software space, you find more claims about the promises of deep learning. Certainly, AI is an extraordinary tool; it’s probably the most extraordinary advance in computer science in our lifetimes. But nothing is perfect.
Deep learning and AI have tremendous potential, but the field is also rife with challenges. Artificial intelligence still cannot perform as well as human beings in an incredibly wide range of tasks, and, in some cases, it’s possible it never will. Decision-makers at technology companies must think carefully about the limitations of deep learning as well as its growing list of accomplishments in an effort to avoid overhyping the technology or making unrealistic claims.
But when you understand the basics of deep learning vs. machine learning—and how they play into today’s AI-heavy environment—it’s easier to separate the hype from the true promise of this advancing technology. Hopefully this guide will help.
To learn more about how neural TTS can help your brand stand out in the Internet of Voice, read this next.


